ChatGPT Image Inputs Use Cases

With the default GPT-4 model in ChatGPT Plus you can now attach images to a conversation. I assume, it uses the model gpt-4-vision-preview under the hood. When I write GPT-4 here, I mean the vision variant.
You can upload PNG or JPEG images of up to 20 MB in size. You can also upload more than one image in a conversation.
Here are some examples of what you can do with image inputs. Right now, chats with images cannot be shared. This is why I included the conversations in part, here:
Understanding Complex Diagrams
GPT-4 can understand complex diagrams and explain them in simple terms. This is for example useful for
- helping you learn,
- creating captions, and
- describing images.
Here is an example of how ChatGPT with GPT-4 interprets a Kubernetes architecture diagram and GPT’s interpretation of it. This was generated with a simple prompt and the first attempt was already quite good:

Identifying Sources and Interpreting Art
GPT-4 can identify a large number of objects and state their source. It can also interpret the objects and classify them into artistic styles or similar categories. This can for example be applied to
- art,
- memes,
- concepts,
- architecture,
- furniture, and
- fashion.
Here is an example that GPT-4 can identify and nicely interpret a sculpture by Jeff Koons. This sculpture was on display at Galerie Max Hetzler in Berlin. If you are interested in modern art and stay in Berlin, you should consider visiting it.

This was generated with a custom instruction, again at first attempt. The custom instruction was:
1
2
3
4
I am a student of modern art and want to understand
who created an artwork and how it can be interpreted.
Please create brief answers.
Translating Text in Images
GPT-4 can also identify and translate text in images. This is for example useful for
- learning,
- understanding, and
- communicating.
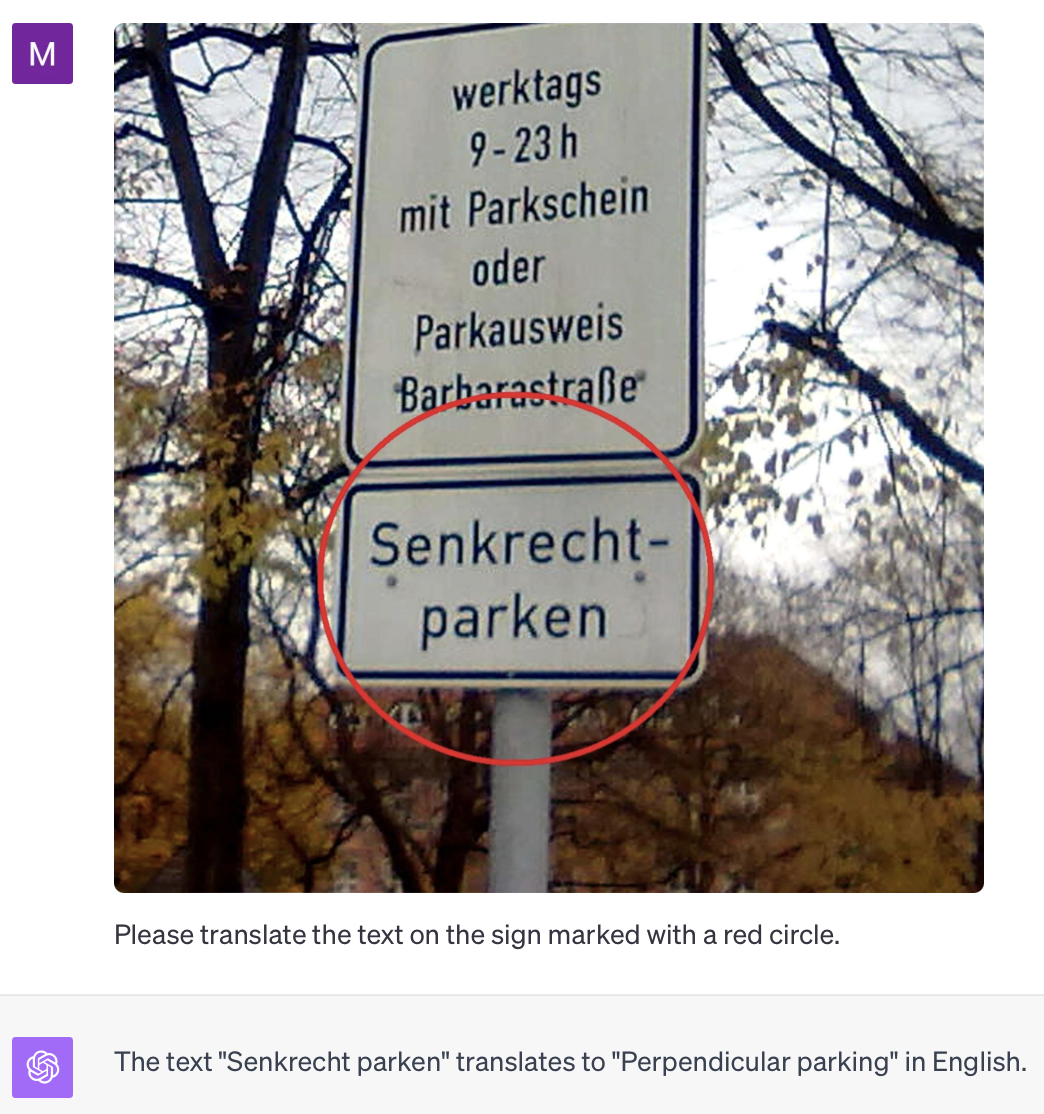
I believe you might get more robust results when you use GPT-4 with specialized OCR models in combination, but this is already quite good. The custom instruction was:
1
2
3
4
I am a visitor to Germany from Australia
and cannot understand German.
Please create brief answers.
Writing Code Based on Images
as GPT-4 can both interpret images and write code, you can use it to generate code based on an image. Here is an example for html and css code, but this also works for database code (SQL), Python code, or other code such as Mermaid diagram code:
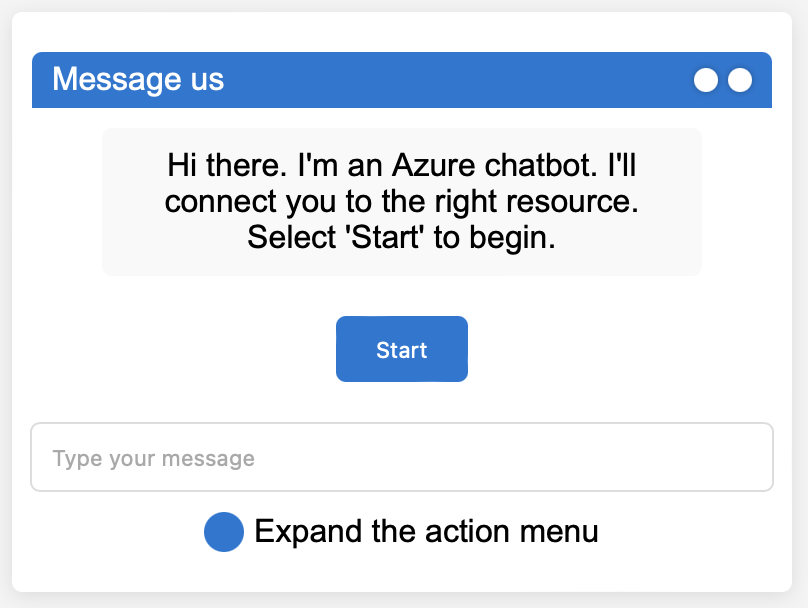
This is Azure’s chatbot box. Can ChatGPT generate HTML and CSS code to replicate it?
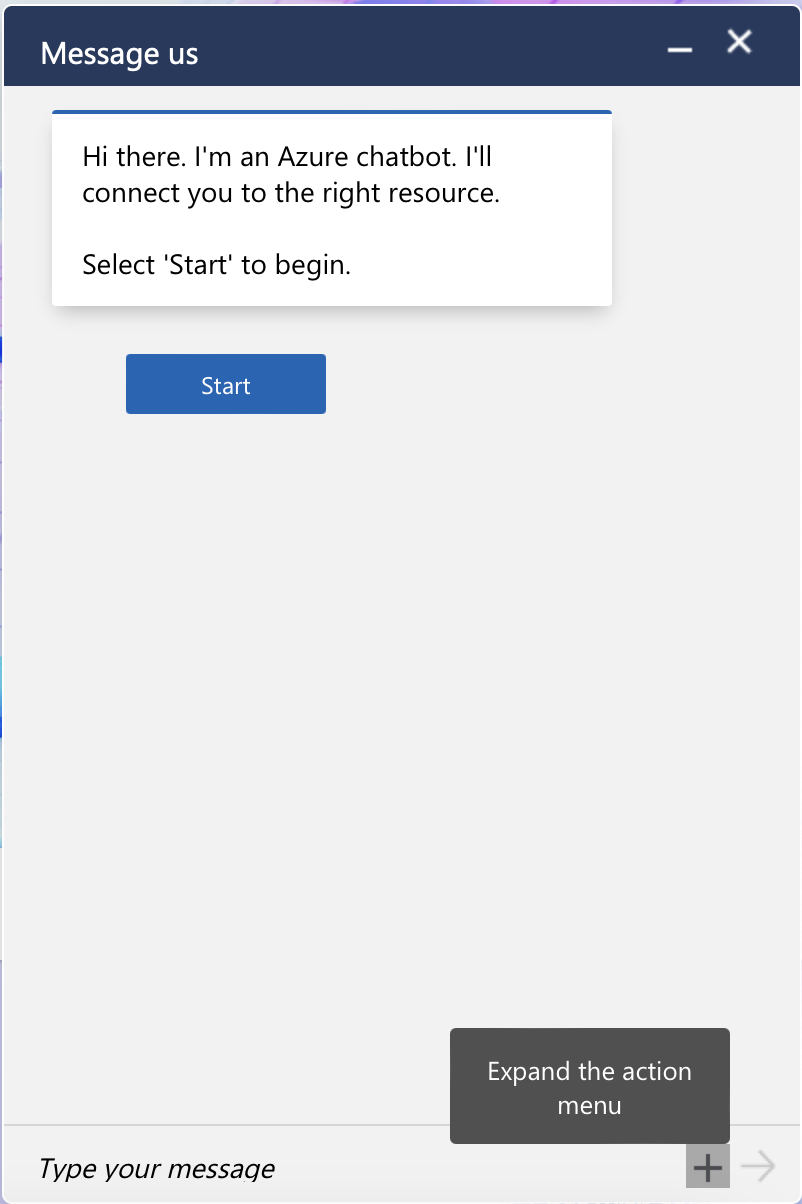
I gave ChatGPT some custom instructions:
1
2
3
4
5
I am a web developer and need to
convert designs into HTML and CSS.
Please create working html with
embedded css code without explanations.
Then, ChatGPT replied with generated code. Here is an image of a browser render of it:
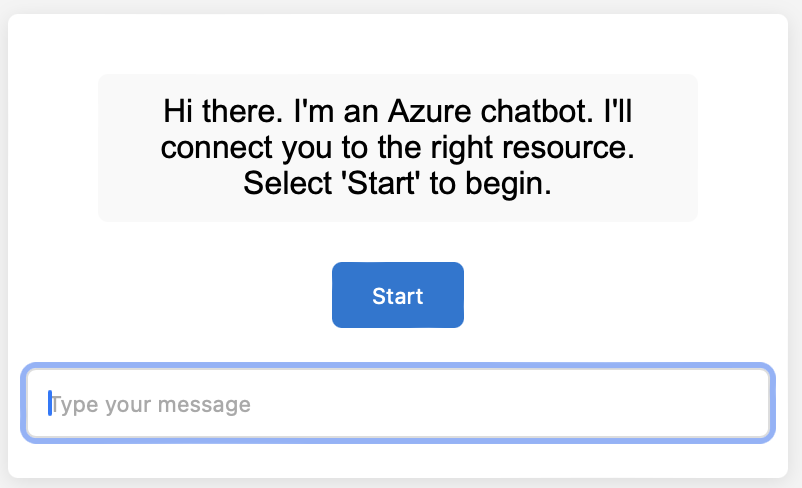
Iterating on Generated Images
As CPT-4 can use Dall-E to generate images, you can use it to iterate on image inputs by generating new images based on previous images combined with further instructions. With this, you can have a bit more control over GPT-4 when it is creating images for you.
As the result of above code can also be captured as an image, I wondered if I could use iteration to improve the result.
I took an image of the browser rendering, manually listed differences between the original and the generated image, and asked ChatGPT to improve it.
The improved code already looks quite usable:
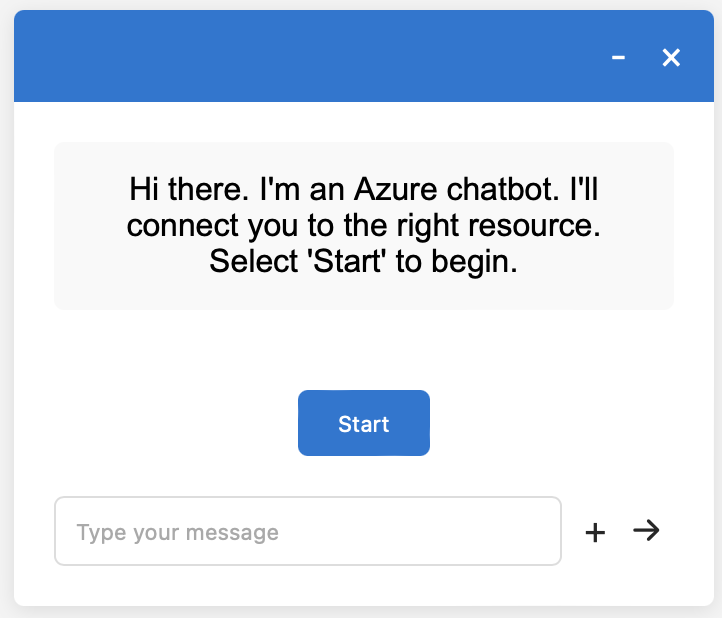
Comparing, Selecting and Ranking Images
GPT-4 can compare images and select one out of a few images or rank images based on defined criteria.
Here is an example that identifies differences between images replacing the manual step I did, above. I removed the “without explanations” from the custom instruction and prompted as follows.
1
2
3
Briefly list the elements missing
in the first picture as compared to
the second picture.
And here is the result:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
The elements missing in the first picture as
compared to the second picture are:
1. The "Message us" title at the top.
2. The window control buttons (-, ×) at
the top right.
3. The "Expand the action menu" text and
associated icon at the bottom right.
Note: The first image is a mobile view and
the second is a desktop view, which typically
have differences in design due to screen
size constraints.
I then used this to ask GPT-4 to create a second, more automatically improved version of the code. The result is not as good as the improved code, where I manually described the differences, but still better than the original version:
Conclusion
The capabilities of this feature are impressive and I am sure that multimodal models will enable many new use cases.
Even with simple prompts I got quite good results even on first attempts.
Simple tasks like describing images and identifying image sources are more robust than more complex tasks like code generation. Even with basic prompts, GPT-4 performs simple tasks robust enough for production.
I assume, more complex tasks like image-informed code generation can be made production-ready with better prompt engineering and by combining GPT-4 with specialized models, such as for optical character recognition, and image segmentation.